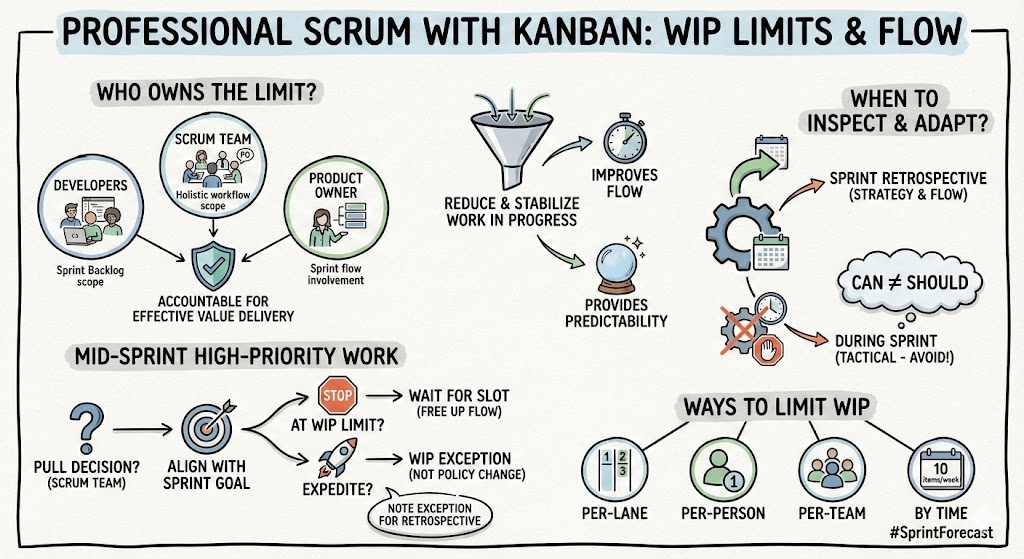
AI Coding Made Code Review the Bottleneck. Now What?
When AI coding increases the arrival rate of pull requests, asking reviewers to work faster is the wrong response. Use end-to-end feature flow, spec-driven development, and the Theory of Constraints to improve reviewability and business throughput.
 Click image to open full size
Click image to open full size How Should Teams Fix the Code Review Bottleneck Created by AI Coding?
AI coding is increasing the arrival rate of pull requests faster than many teams can review them. The result is predictable: growing review queues, larger batches, rubber-stamped approvals, and more cognitive load concentrated on the few people who understand the system deeply. That is not evidence that AI coding failed. It is evidence that the constraint moved.
The practical response is to manage the flow of features or specs from idea through validation, not just the speed of coding tasks. Then apply the Theory of Constraints: identify review as the current constraint, make each change easier to review, subordinate new starts to review capacity, add capacity only when better review would increase business throughput, and repeat when the bottleneck moves again. Spec-driven development helps when it improves the review packet and catches bad direction before code exists. It hurts when it simply generates more detailed work for humans to inspect.
Faster coding changes the question
A founder recently asked a useful question in a Spec-Driven Development discussion on Reddit. AI-assisted coding can help individuals move faster, but who makes sure those changes fit the product, avoid cleanup elsewhere, receive a meaningful review, and are safe to release?
That work often lands on the same few people: the founder, CTO, senior engineer, architect, security specialist, or whoever remembers why a strange-looking part of the system exists. AI can increase coding capacity without increasing the attention, context, or judgment available from those people. The team can generate ten times as much code. It cannot generate ten times as much trusted review from the person who has spent six years learning where the bodies are buried.
I am hearing this concern in conversations with scaled engineering organizations and people working across the CI/CD ecosystem. I also see the pattern when looking at internal and public repositories: more agent-assisted changes can create a very real PR review bottleneck.
One team is responding by making every change as easy to review as possible. They are building what I would call a “full kit” review packet. The reviewer should not have to reconstruct the goal, hunt for the relevant spec, guess what changed, figure out the risk, discover how it was tested, and then decide what deserves close attention. The change arrives with that context already assembled.
That is a smart move. But it is one move inside a larger constraint-management problem.
Measure feature flow, not coding speed
The first mistake is measuring the part that AI has already made fast. If you track time from “agent started” to “code generated,” you will prove that AI generates code quickly. That tells you very little about whether the product is moving faster or becoming safer.
I prefer to manage the flow of features or specs. That is the useful altitude for seeing whether the new engineering speed is improving delivery or simply feeding another queue.
A lightweight workflow might look like:
- Thinking and ideation
- Discovery and de-risking, when needed
- Specify, build, and test
- Review
- Deploy
- Validate and tweak
This was my metrics reply in the thread, lightly edited for readability:
I would suggest a definition of workflow that lets you see how much time a spec spends in each major area of the process: thinking and ideation; discovery and de-risking when needed; specify, build, and test, probably as one lane; review; deploy; and validate or tweak.
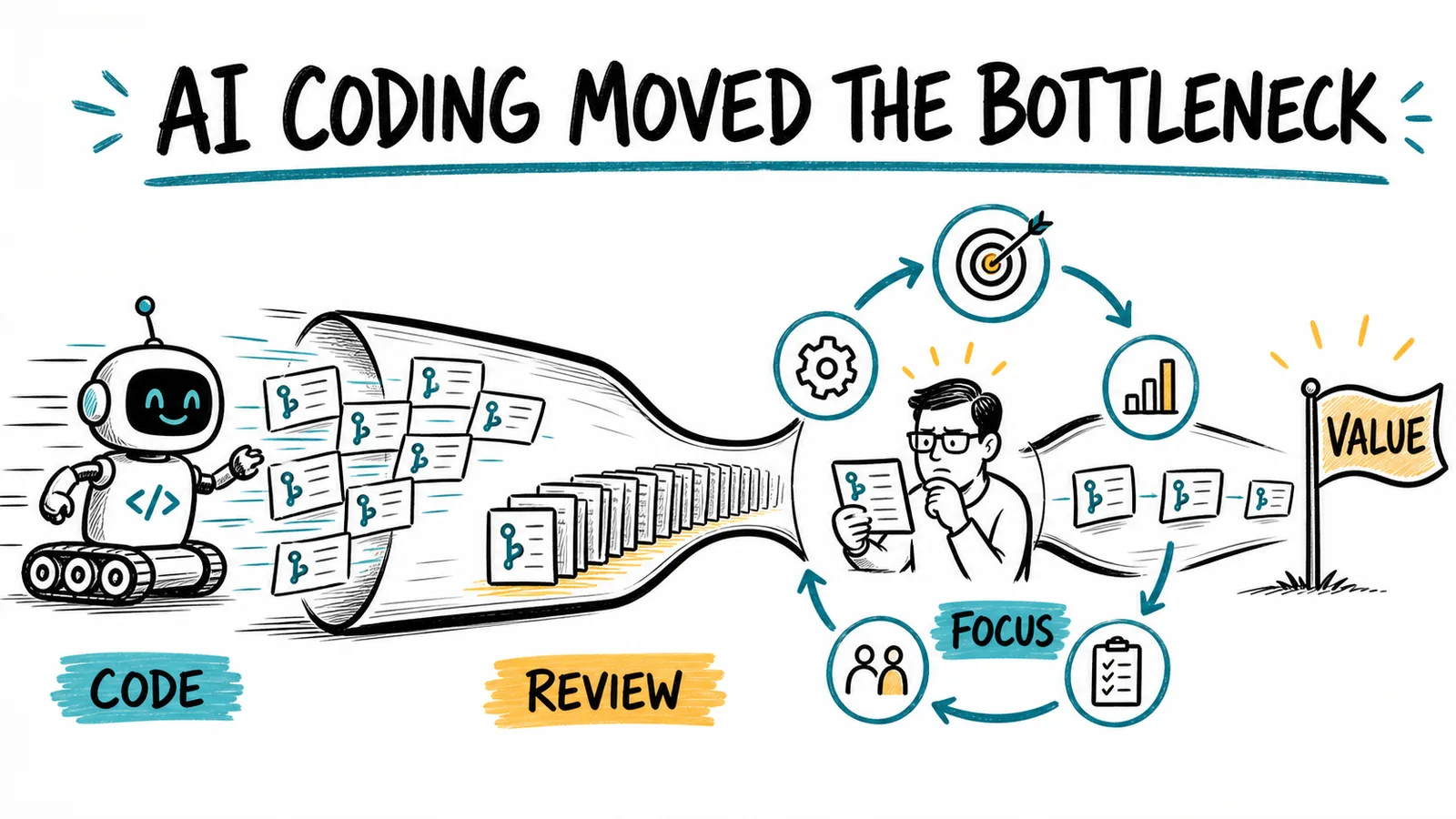
That is the biggest gap I see when I look at most repositories, or even Jira and Linear. People focus on the lifecycle of stories, which now move too fast to be interesting to track. They do not focus on feature flow end to end.
Measure cycle or flow time end to end, not only for specify and build. Look for anomalies. Look at a cumulative flow diagram to understand internal cycle times in different sections, the overall load and WIP, and emerging bottlenecks in specific sections.
An SDD Kanban view makes this flow visible. Instead of treating the pull request as the main unit of work, put each feature or evolving spec on the board and follow it from intent through validation. Show where the spec is emerging, where agents are building, where human decisions or reviews are needed, where deployment is waiting, and where validation has not closed the loop. I describe this view in more detail in Is Spec-Driven Development a Step Forward or Back for Product Development?.
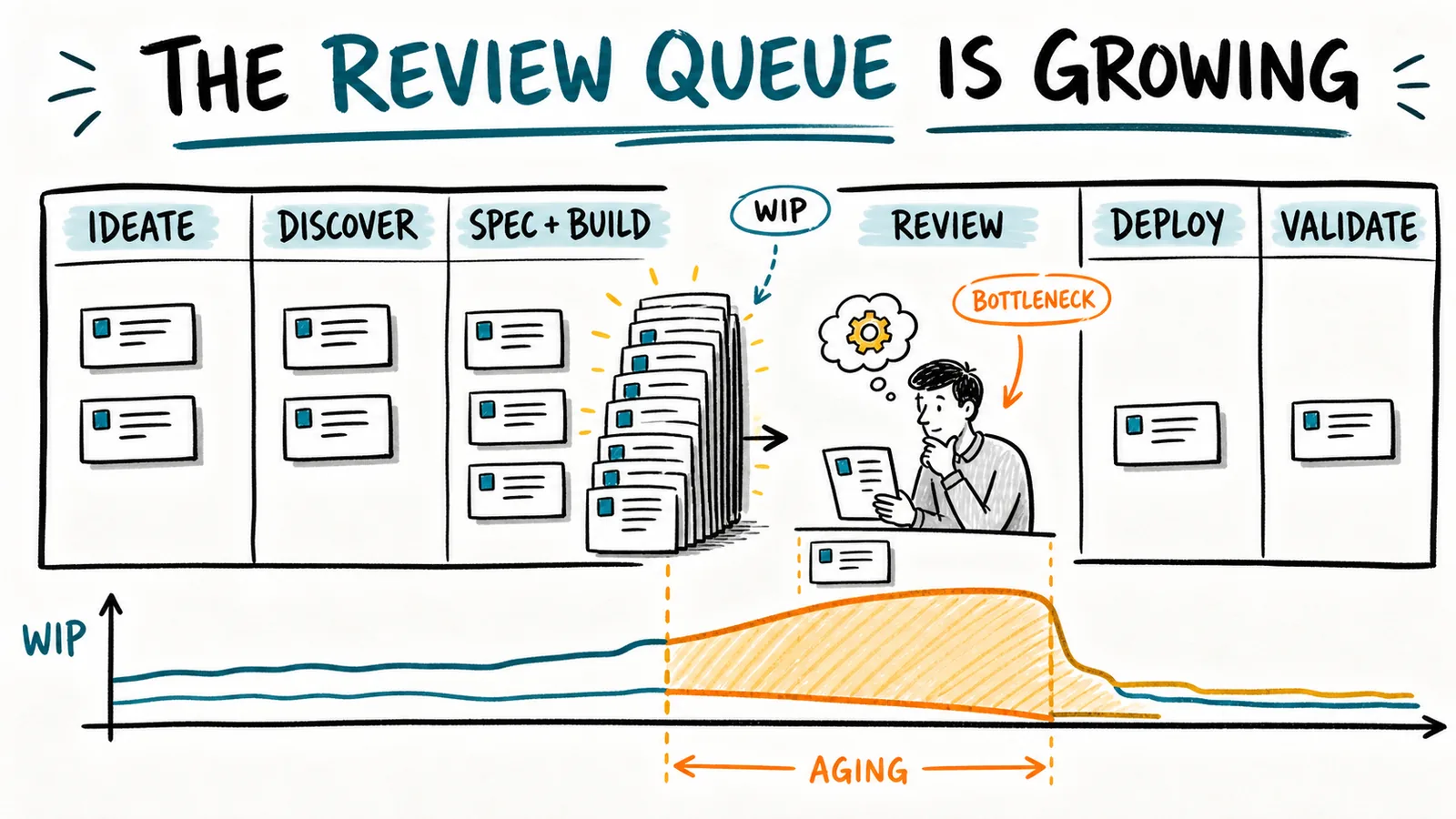
The exact labels matter less than the boundaries. You want to see how much time a meaningful change spends in each major area, how much work is active, and where work is accumulating. Most repository analytics focus on commits, branches, pull requests, and issues. Most Jira or Linear setups focus on the lifecycle of stories. Those views can miss the feature’s end-to-end journey, especially when AI makes individual stories and coding tasks move too quickly to be interesting.
The board gives the team a shared operational view. WIP shows which stage is accumulating inventory. Work item age shows which feature or spec has stopped moving, even if agents are still producing artifacts around it. Blocked markers reveal missing decisions, specialist dependencies, or unavailable environments. A cumulative flow diagram shows whether the review band is widening over time. Together, these signals help distinguish a noisy queue from the constraint that is actually limiting end-to-end flow.
Measure cycle time across the whole flow, not only specify-build-test. If completed implementation is accumulating faster than reviewed, deployed, or validated changes, the SDD Kanban view is telling you where to investigate. Then use the outcome and validation stages to confirm whether clearing that queue would improve business throughput or merely move more inventory downstream.
PR-level signals are still useful. Review queue size, time to first meaningful review, PR age, batch size, rework after review, and concentration around a few reviewers can help explain the bottleneck. But do not confuse the queue with the value stream. A team can make PRs move faster while features still wait for deployment, adoption, or evidence.
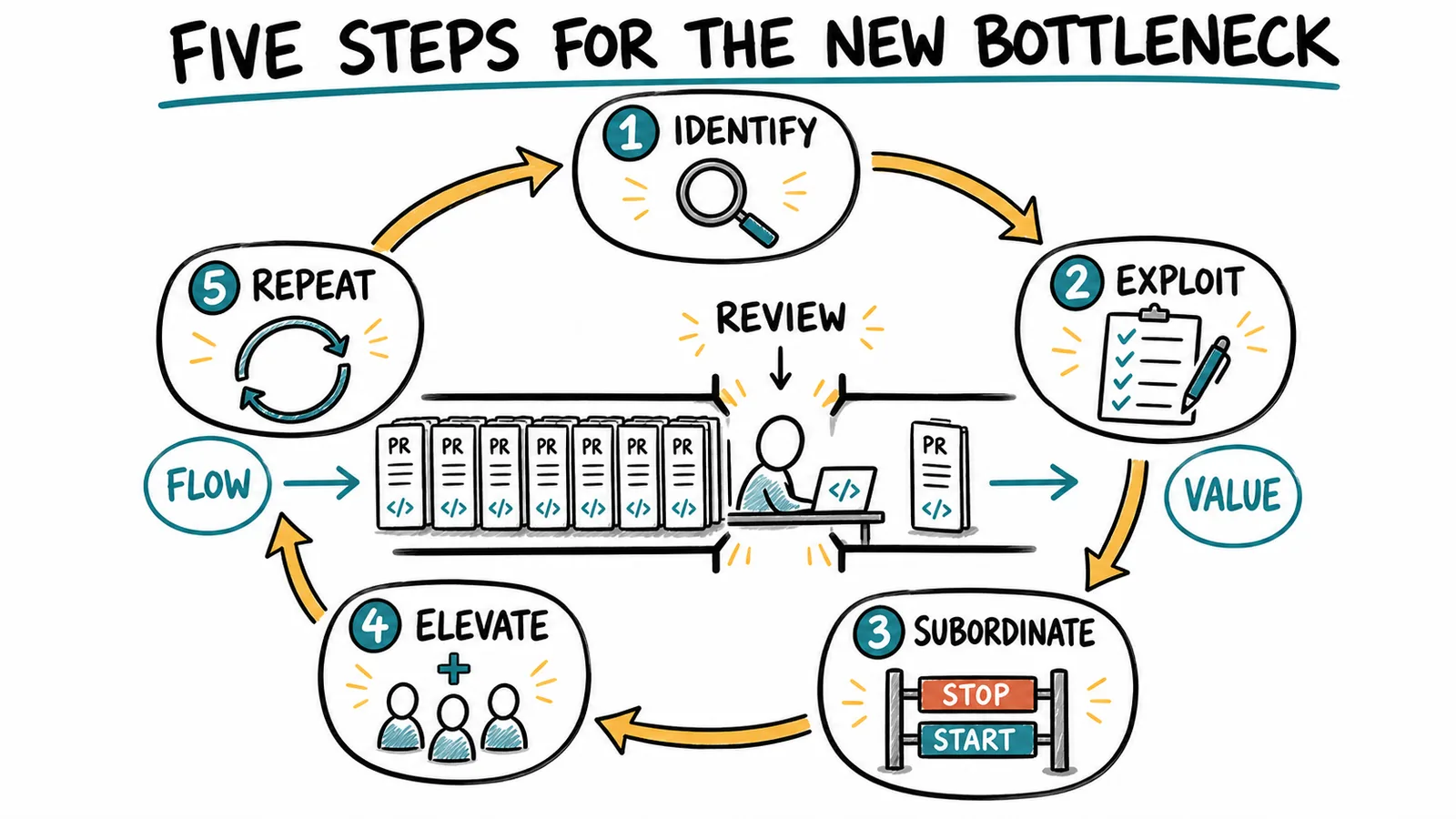
These metrics connect directly to the five focusing steps:
- Identify: End-to-end cycle time, WIP, work item age, stage-level time, and the cumulative flow diagram show where work is accumulating and which stage is limiting feature throughput.
- Exploit: Review time, batch size, rework, and time to first meaningful feedback show whether review packets, smaller changes, and agent pre-review are making scarce reviewer attention more effective.
- Subordinate: WIP before review, arrival versus departure rate, and the age of waiting specs tell the team when to stop starting and move capacity toward finishing.
- Elevate: End-to-end throughput and downstream cycle time show whether adding review capacity would produce more validated value or merely move the queue to deployment or adoption.
- Repeat: The same Kanban and cumulative flow views reveal where the accumulation appears next after review improves.
Apply the five focusing steps to code review
The Theory of Constraints gives teams a practical way to respond without turning this into another AI tooling program. The five focusing steps are identify, exploit, subordinate, elevate, and repeat. Here is how I would apply them when human code review becomes the constraint.
1. Identify the real constraint
Start with flow, not opinions. Is code review actually constraining completed, valuable changes? Or is it simply the loudest complaint?
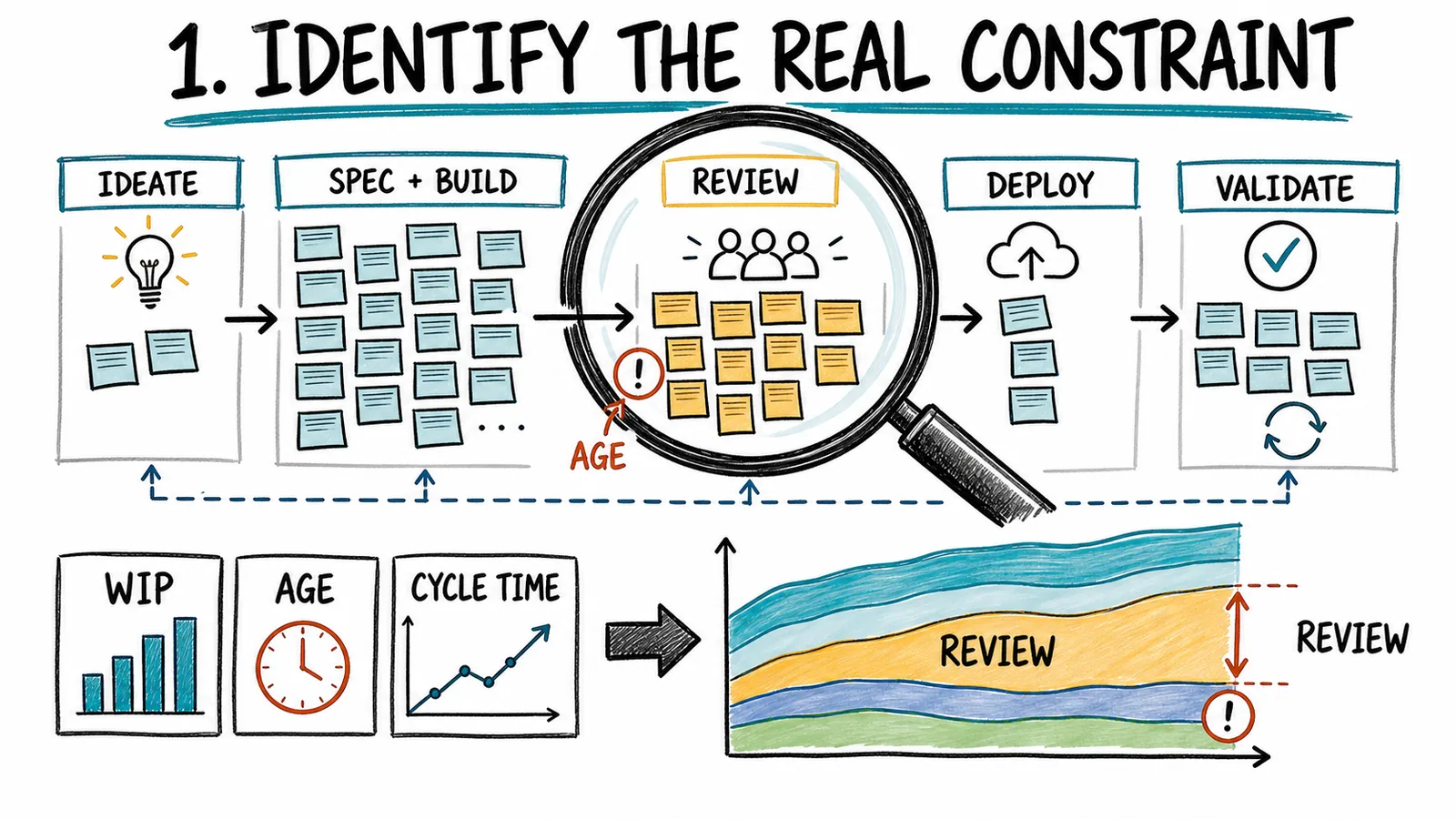
Use the SDD Kanban view to look for work accumulating before review, aging features and specs, PRs waiting on the same specialists, or review shortcuts that later show up as rework and production risk. Compare the arrival rate with the departure rate. If agents and developers open changes faster than reviewers can understand and clear them, review is a likely constraint.
Then zoom back out. If reviewed code waits another three weeks for deployment, review might not be the system constraint. If shipped features sit unused, adoption might be the constraint. If the team is building weakly validated ideas, product judgment may be the constraint even though the pain first appears in the PR queue.
This is why feature-level flow matters. The constraint is the part limiting end-to-end throughput, not necessarily the busiest stage.
2. Exploit the review constraint
“Exploit” sounds harsh when the constraint is a person. The intent is not to squeeze more reviews out of someone. It is to use scarce review attention as effectively as possible.
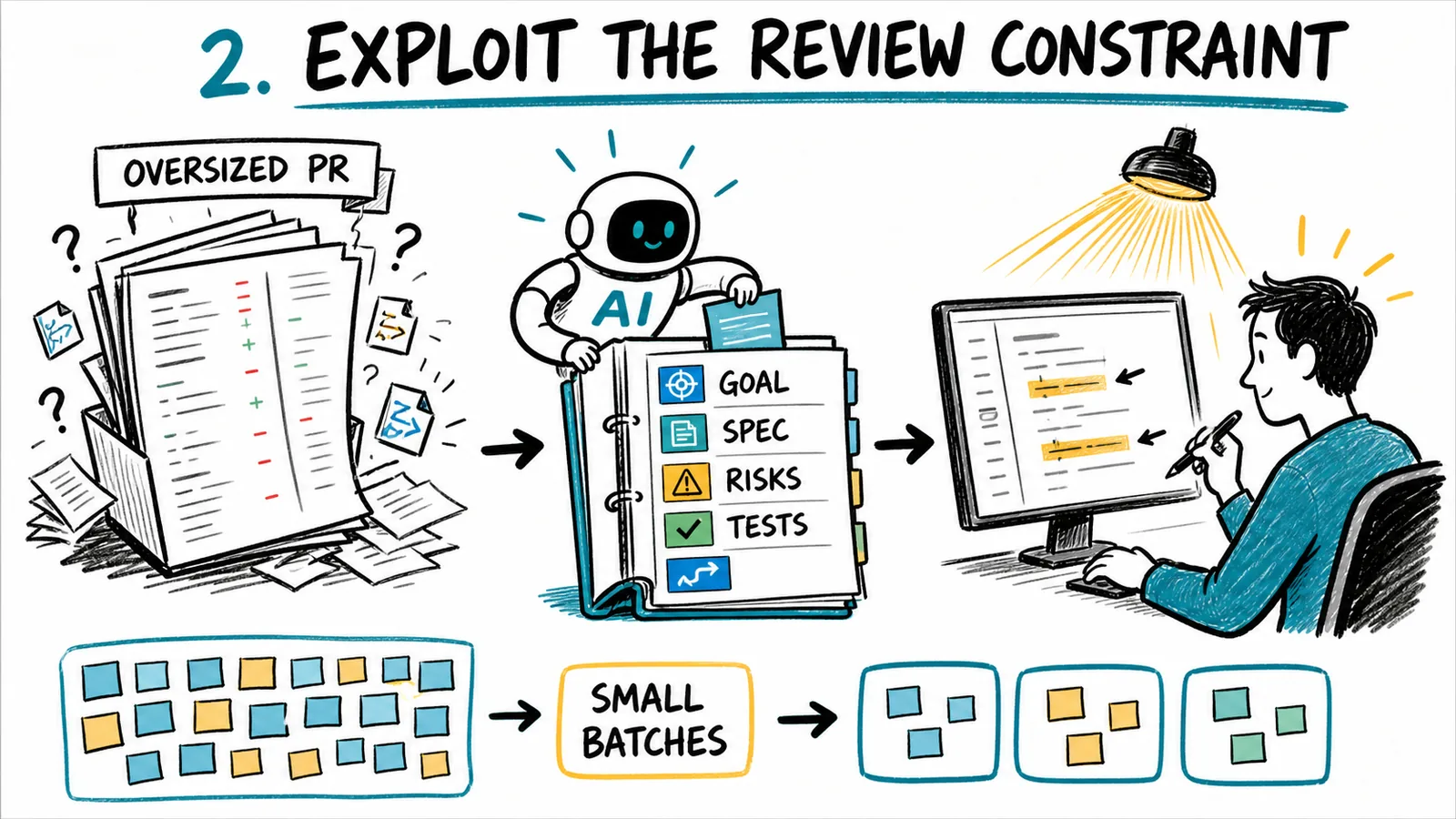
Start by telling your coding agents that human reviewability is a design constraint. Do not wait until the pull request exists. Ask the agent to optimize the entire change for a reviewer who has limited time and did not participate in the implementation.
A useful review packet might include:
- The goal and user or business reason for the change
- The approved spec or decision record
- A short map of what changed and what deliberately did not
- The highest-risk areas and assumptions
- Test evidence and important scenarios
- Screenshots, traces, or before-and-after behavior where useful
- Known limitations and follow-up work
- A suggested review path through the files
This is where spec-driven development can earn its keep. The spec becomes part of the review interface. It gives the reviewer something more useful than a diff: the intent, constraints, acceptance criteria, and decisions the code is supposed to express.
Agents can also perform a pre-review from several perspectives: correctness, security, architecture, tests, duplication, backwards compatibility, and alignment with the spec. They can summarize generated or mechanical changes and flag the sections where human judgment is needed. The goal is not to replace the accountable reviewer with another model. It is to stop spending scarce human attention on work a machine can do well enough before the review starts.
Small batches matter too. A beautifully documented 4,000-line PR is still a 4,000-line PR. Reviewability is shaped by architecture, slicing, naming, test design, and the sequence of changes, not only by the quality of the summary.
3. Subordinate everything else to review
This is the step most teams skip.
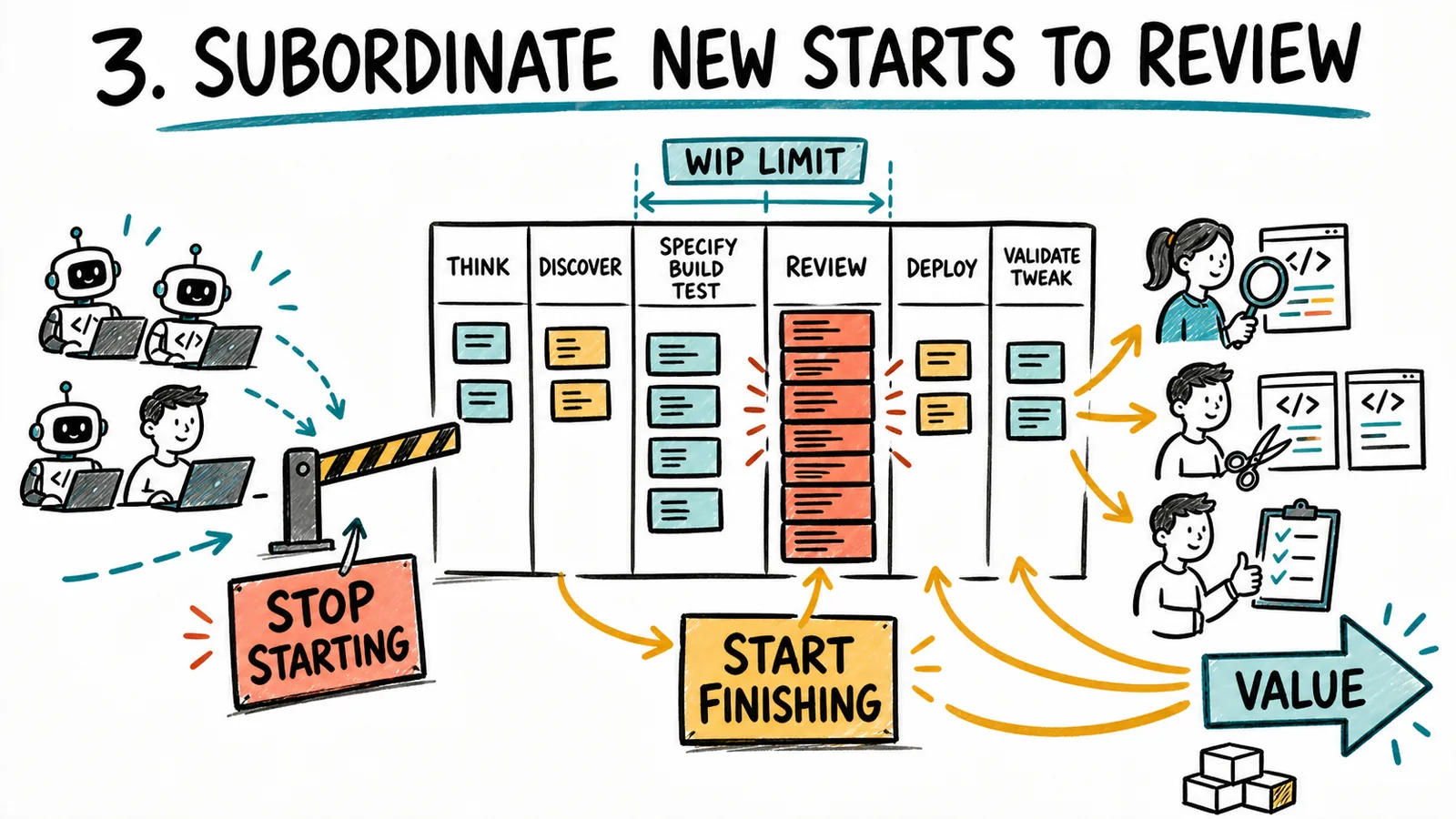
Once review is the constraint, the rest of the system should operate in a way that helps review produce more completed value. That may mean agents use more tokens to create better tests, clearer explanations, smaller commits, and stronger review packets rather than starting another feature. Local AI efficiency is irrelevant if it increases the load on the constrained stage.
It may also mean limiting the number of specs or pull requests waiting for review. When that limit is reached, stop starting and start finishing. Shift human capacity from specifying and building new work toward reviewing, pairing, testing, or helping split risky changes. Do not let every developer-agent pair keep producing because their local lane is available.
Subordination reaches further upstream. Make sure the team is working on the right features and testing the riskiest assumptions without code when possible. Every low-value feature that reaches review consumes the same scarce attention as a valuable one. When review is constrained, weak prioritization becomes very expensive.
This is also where SDD can go wrong. If spec-driven development produces more specs, more parallel agent runs, and more completed branches awaiting approval, it increases inventory around the constraint. A good SDD workflow should control WIP, expose assumptions early, and make review easier. It should not become a faster feature factory with nicer Markdown.
4. Elevate review capacity carefully
After you have improved reviewability, reduced batch size, automated appropriate checks, and subordinated new starts to review capacity, review may still be the constraint. Now consider elevating it.
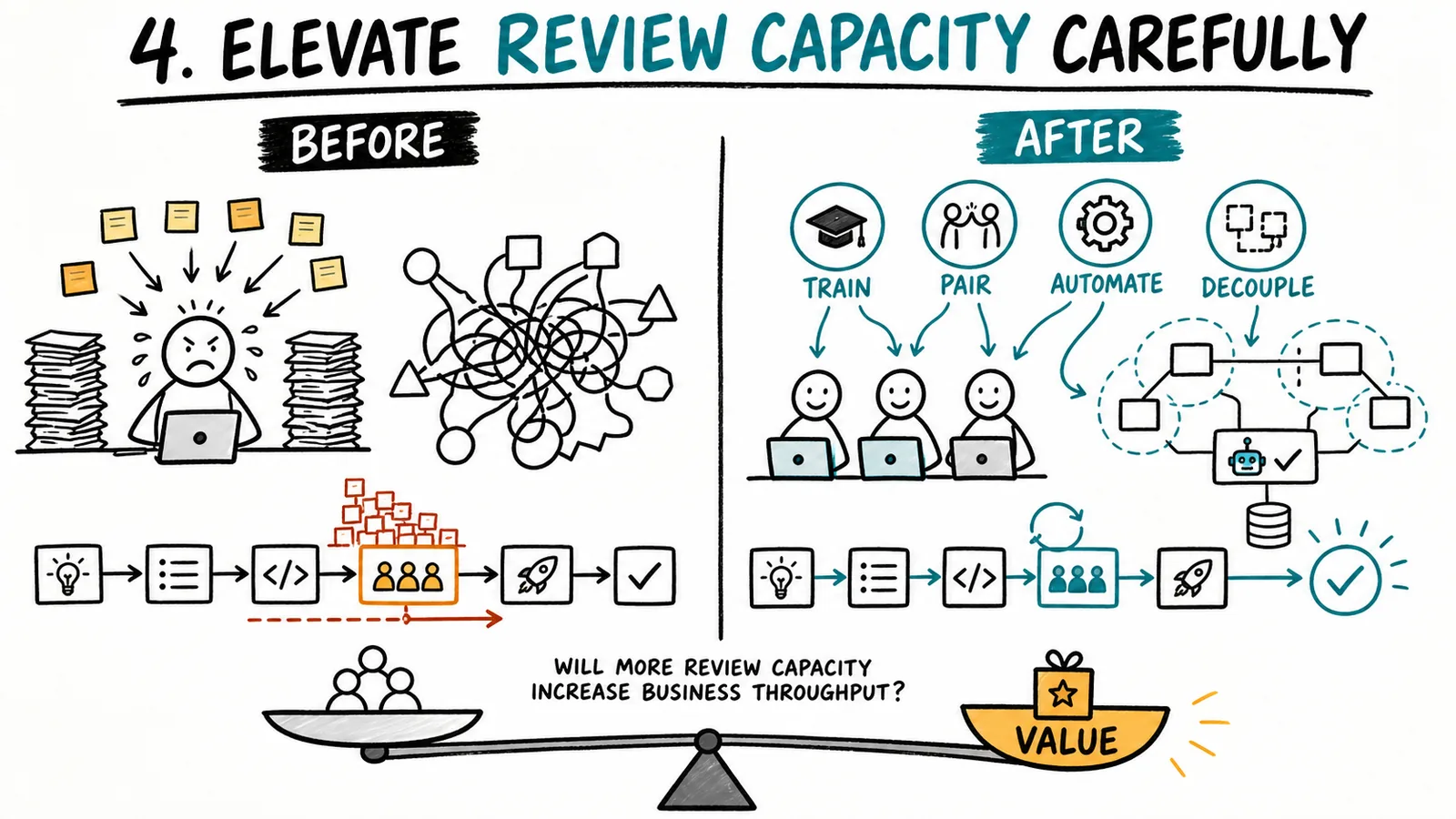
Elevation might mean adding reviewers, developing more people who understand the architecture, creating clearer ownership boundaries, improving test environments, changing the architecture to reduce coupling, or reserving explicit review capacity. Pairing and collaborative development may reduce the need for a separate late review on sensitive work because understanding is built while the change is being shaped.
But adding review capacity is not automatically a good investment. Ask whether clearing more reviews will increase business throughput. If the next constraint is deployment, adoption, customer validation, or decision-making, you may simply move more inventory downstream.
Scale the constraint when the additional capacity turns into more useful, safe, validated outcomes. Do not scale it because the queue is annoying.
5. Repeat when the bottleneck moves
If the team improves review, the constraint will move. That is success, not failure.
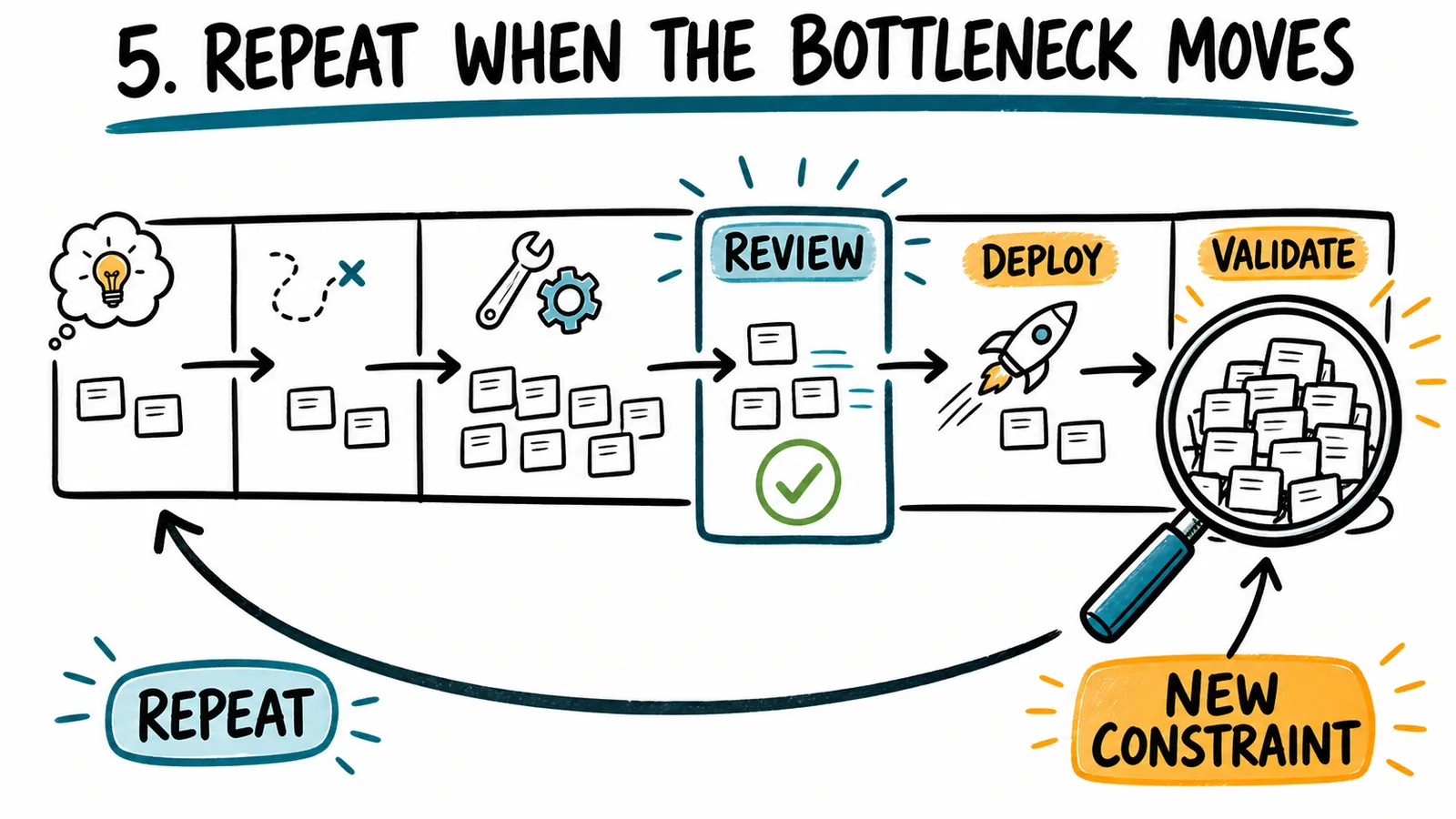
You may discover that deployment is now the slow stage. Or that the organization can deploy quickly but cannot validate whether changes mattered. Maybe product discovery cannot provide enough well-shaped, high-value opportunities. Maybe one architectural boundary keeps creating cross-team review dependencies. Maybe customers cannot absorb the pace of change.
Go back to the flow. Identify the new constraint. Apply the same steps again.
AI coding will keep changing the relative capacity of different parts of the system. A static process will age quickly. The capability you need is not a permanently optimized code review process. It is the habit of seeing and managing a moving constraint.
Review the plan before the diff
One reply in the Reddit discussion made the point bluntly: reviewing the plan before code is generated is the only way to fix this because the diff is too late. I would not make that absolute, but the direction is right.
The most valuable review often happens before the agent has generated thousands of plausible lines. Review the goal, boundaries, risks, acceptance criteria, architecture direction, and validation approach. Catch the wrong idea, oversized slice, missing constraint, or dangerous dependency while it is still cheap to change.
That does not require a giant up-front specification. The spec should be detailed enough for the risk and reversibility of the decision. A small, reversible change may need a short goal and a few examples. A sensitive migration may need a careful plan, explicit invariants, rollback thinking, and review gates before implementation proceeds.
The point is to move human judgment earlier without recreating waterfall. Specs should evolve as the team learns. Agents should surface decisions and uncertainty as they work. Review should happen at meaningful decision points, not only after the code is “done.”
A prompt to try with your own context
Try asking your AI:
How would you apply the Theory of Constraints five focusing steps to the code review bottleneck resulting from AI coding?
Then give it real context. Describe your feature workflow, review queue, WIP, cycle-time breakdown, PR size and age patterns, specialist dependencies, deployment flow, and how you validate value after release. Include your current SDD process and an example review packet.
The generic answer will be reasonable. The useful answer starts when the AI can see your actual system.
The real goal is not faster review
If AI coding has made code review painful, do not treat that pain as a reviewer productivity problem. The queue is telling you something about the system. Code is arriving faster than trusted judgment can absorb it.
Make the work easier to review. Use specs to carry intent. Let agents do more preparation and pre-review. Limit work waiting at the constraint. Move human attention from new starts to finishing. Add capacity only when it improves the flow of valuable outcomes.
And keep measuring above the PR level. The goal is not to merge AI-generated code faster. The goal is to move the right features from idea to validated impact without burying your best people in a review queue.
AI did not remove the bottleneck. It made the next one easier to see.
Practical thinking on turning AI pilots, adoption, and portfolio work into business impact - by finding the constraint, changing the work, and proving value as you go.
Yuval Yeret helps product and tech leaders move from agile theater to evidence-informed delivery. Work with Yuval →