An Operating System for AI-Native Teams: From Activity to Impact
AI agents generate code faster than ever, but the bottleneck has shifted to human decision latency and review capacity. Here is the operating system that closes the gap between AI activity and business impact.
The Bottleneck Moved, and Your Operating System Didn’t Follow
Organizations are investing heavily in AI co-pilots and specialized developer agents, generating code faster than ever before. Yet tech leaders are sensing a frustrating reality: the work is visible, but the value is not. Code velocity is up, review backlogs are piling up, and business impact is flat. The bottleneck didn’t disappear. it shifted from syntax writing to human decision latency and review capacity. Your operating system needs to follow.
The fix isn’t another tool or more meetings. It’s an operating system for AI-native teams that manages human intent, embeds operating rules as an ambient intelligence layer directly into the flow of work, and validates outcomes instead of counting outputs. This guide outlines that operating system. framework-agnostic, focused entirely on the behaviors, outcomes, and heuristics needed to shift teams from AI Theater to true value realization.
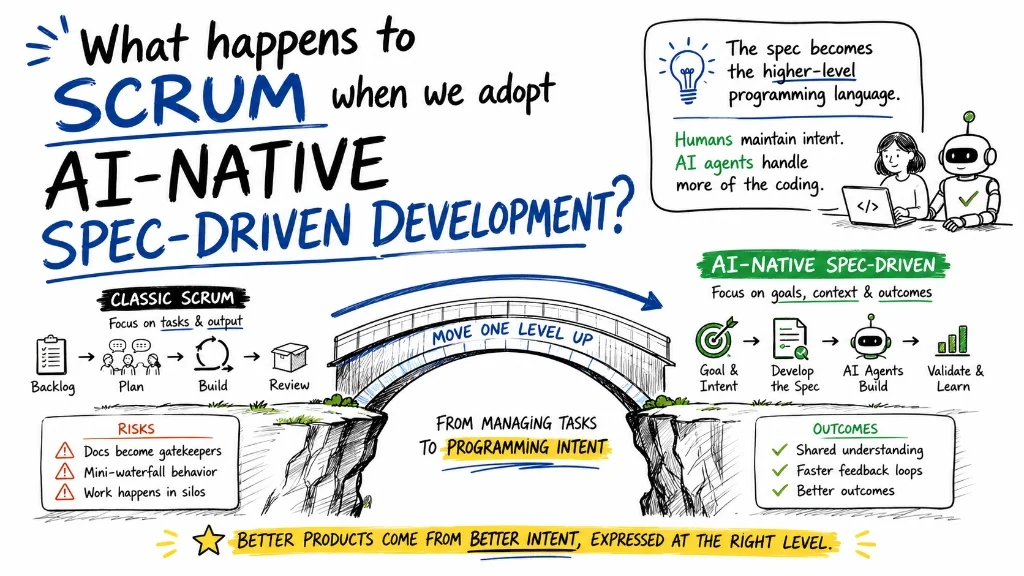
The Core Shift: Managing Human Intent, Not Code Syntax
In traditional software development, team complexity was split between defining “what” to build and figuring out “how” to write, debug, and configure the code. The “how” was the expensive part. it consumed the majority of engineering time, attention, and capacity. When we adopt AI-native development, the low-level “how” (syntax, API wiring, boilerplate) is largely offloaded to AI agents. But defining the “what” and validating the “why” remains highly complex. The bottleneck has shifted from syntax writing to human decision latency and review capacity, and most teams haven’t noticed.
If you inspect only outputs. lines of code generated, pull requests merged, tickets closed. AI will make your metrics look spectacular while your product rots. This is Requirements Theater with better tools. The empiricism that matters now operates at a higher altitude. Transparency means making the human intent. our assumptions, risks, and learning strategy. visible in the specifications we give to the AI, not just in the generated code. Inspection shifts from “did the developer write the code correctly?” to “does the behavior of the system match our business hypothesis?” Adaptation means changing the specification and the underlying business model as soon as we observe that our assumptions were wrong. If your team is still measuring story points and velocity, you are inspecting the wrong layer of the system.
Leveled-Up Human Accountabilities
Because AI agents absorb the manual coding tasks, the human team must shift their focus to intent, architecture, and systems engineering. This is not a minor adjustment. It is a fundamental redefinition of what engineers and product leaders spend their time on. And it comes with a hard rule that is easy to forget in the excitement: AI agents do not have accountability because a tool cannot bear accountability. Every decision, every release, every validation still lands on a human.
Instead of assigning rigid titles, teams should ensure three accountabilities are actively managed. The first is owning the business outcomes. operating at the level of business yield, defining the expensive problem, the constraints, and the leading indicators of success, rather than micro-managing task details. What great looks like: the person owning the outcome provides clear context and goals that prevent AI from hallucinating business value. The second is architecting intent and specifications. authoring the specifications that define context, constraints, examples, and validation parameters, which now serves as the high-level programming language for the AI agents. What great looks like: engineers program the system by writing clear, atomic intent documents and spend their time reviewing AI output for structural integrity rather than writing boilerplate. The third is coaching the operating model and flow. designing the human-agent operating model and managing the team’s cognitive load, protecting them from coordination tax and context switching. What great looks like: someone acts as an ambient observer, stepping in when the team is overloaded with unreviewed AI code or suffering from context drift.
The Continuous Execution Loop
The team operates in continuous, rapid cycles of learning. They decompose high-level goals into detailed specifications, AI agents execute against those specifications, and humans verify the results. This is not Sprint Planning versus Kanban. it is the loop that actually matters when code generation is fast and the constraint is human attention.
The loop has five checkpoints that replace the ceremony-heavy cadences most teams inherited from pre-AI agile. The Focus Cycle is a bounded timebox used as a risk-mitigation container to validate assumptions before writing miles of code; capacity estimation is replaced by focus. Intent Alignment is where the team aligns on why this cycle is valuable and how they will swarm around the work. human-AI pairing for high-risk work, individual agent swarms for well-specified work. Steering Syncs are daily human checkpoints to inspect emerging learning, surface architectural drift, and catch specification errors early before they compound. Outcome Validation is where the team inspects actual user data and business yield to determine if the work solved the target problem, not just a feature parade. System Retrospectives are for reflecting on the efficiency of human-agent interactions, updating guardrails, and tuning prompt patterns to improve the system itself.
Flow heuristics keep the loop from jamming. Finishing over starting: humans and agents must prioritize completing and reviewing open specifications before starting new ones. a stack of half-finished specs is where value goes to die. Batch sizing: keep specifications atomic, because monolithic requests degrade agent performance, increase context-window costs, and complicate human reviews. WIP limits: limit the number of active capabilities assigned to a single human to prevent review fatigue and coordination bottlenecks. If your developers are reviewing five AI-generated PRs simultaneously, none of them are getting real scrutiny.
The 5-Layer Ambient Intelligence Model
Rather than enforcing a rigid, prose-heavy framework, teams should embed their operating rules directly into the flow of their work as an ambient intelligence layer. This provides continuous sensing and coaching without requiring everyone to read a process document and remember it. The model has five layers, each with a concrete behavior.
The Safety Boundaries Layer defines non-negotiable principles and accountability. A work item is never assumed “Done” by an AI. It must conform to the verification plan, pass automated checks, and be reviewed by a human. This is the floor. everything else is negotiable, this is not. The Purpose Layer defines the team’s mission, customer focus, and optimization philosophy. The team actively pushes back against high volumes of AI-generated work if it does not clearly move them closer to their business goal. Value over output is not a slogan here; it is a gate. The Preferences Layer shapes local developer behavior and labor division. The team consciously categorizes work into Agent-Led (autonomous), Augmented (human-AI pairing), and Human-Led (AI assisted) modes based on complexity and risk. Not everything should be delegated to an agent, and not everything needs a human in the loop. the team decides deliberately.
The Sensing Layer provides reusable cognitive capabilities running in the background to detect anomalies. The system actively detects Specification Drift. when an agent deviates from the plan. and Work Item Aging. pinpointing bottlenecks where human attention is overloaded. These sensors run continuously so the team doesn’t have to manually hunt for problems. The Event-Driven Triggers Layer ties the sensing capabilities to real-world repository events for non-intrusive feedback. If a human attempts to start too many specifications simultaneously, a trigger asks: “WIP limit reached. You have active reviews pending. What should we stop starting so we can start finishing?” The feedback is timely, contextual, and non-blocking. it coaches instead of enforces.
The tools have changed. The operating system must now follow. When we shift our focus from the mechanics of coding to the discipline of value realization, we create the conditions for unprecedented agility.
Making It Real: A Machine-Readable Configuration
The 5-layer model isn’t theoretical. it can be encoded directly into the repository as an active operational intelligence layer. This transforms the framework from a prose document into something the system actually enforces and coaches on. Here is a framework-agnostic configuration that operationalizes the model:
# .ai-os/config.yaml
# Ambient Operational Intelligence Configuration
safety_boundaries:
enforce_dod: true
quality_gates:
- automated_tests_passed
- lint_errors_zero
- human_code_review_approved
accountability: 'Human review required for all releases to staging/production.'
purpose:
optimization_metric: 'business_yield_over_output_volume'
value_gate: 'Reject high-volume AI output that does not advance the business goal.'
preferences:
wip_limits:
human_driver_max_active_specs: 2
batch_sizing:
max_spec_tokens: 1500
max_pr_diff_lines: 400
labor_division:
default_mode: 'Augmented (Human-AI Pairing)'
modes:
- agent_led: 'Low complexity, low risk'
- augmented: 'Medium complexity or risk'
- human_led: 'High complexity or high risk'
sensing:
active_sensors:
- spec_drift_analysis
- work_item_aging
- flow_constraint_detection
hooks:
wip_limit_breach:
trigger: 'developer_starts_third_spec'
action: 'warn_and_request_override'
message: 'WIP limit reached (Max 2). What should we stop starting so we can start finishing?'
aging_spec:
trigger: 'spec_active_greater_than_24h'
action: 'notify_coach'
message: 'Spec is at risk of starvation or agent loop.'This is not a document you read once and forget. It is a living configuration that your tools, hooks, and sensors read continuously. When the operating system is encoded in the repository, the team doesn’t have to remember the rules. the system reminds them at the exact moment the rule matters.
If your organization is stuck in AI Theater. lots of activity, not enough impact. the problem isn’t the models. It’s the operating system. Start by shifting your inspection from outputs to outcomes. Then embed the rules into the flow of work so they coach instead of constrain. The teams that figure this out first will not just be faster. They will be the ones whose AI investments actually show up on the P&L.
Practical thinking on turning AI pilots, adoption, and portfolio work into business impact - by finding the constraint, changing the work, and proving value as you go.
Yuval Yeret helps product and tech leaders move from agile theater to evidence-informed delivery. Work with Yuval →